Grain Size Distribution in the River Waal
This project focused on generating a spatial model that determines the grain size distribution over locations in the river Waal. At this stage, the scope aimed to achieve a description of baseline patterns. The data is composed of a sieving test database, which contain the diameters of the test sieves and information about the location and year of testing, as well as the morphology of the river. The project included the following steps:
- Hypothesis testing about temporal differences in tests.
- Hypothesis testing about spatial differences in tests
- Dimensionality reduction, because the data lived in a highdimensional space (one feature for each of the examined 22 sieve diameters).
- Hierarchical clustering of the data.
- Spatial modelling via logistic regression (feature selection, cross-validation, setup of the predictive model).
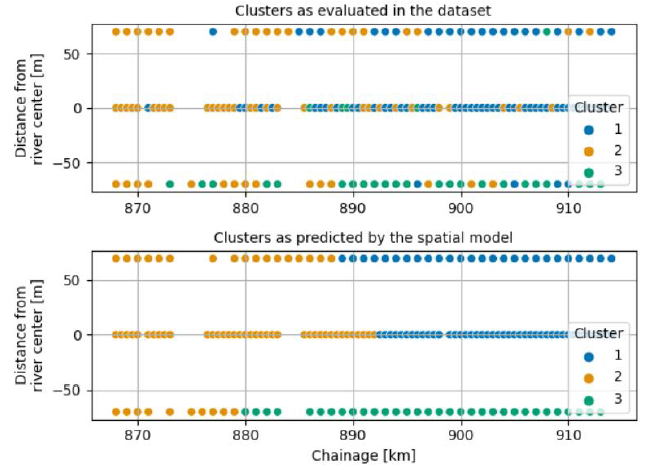
Key Points:
- Hypothesis testing
- Dimensionality reduction of data (PCA, t-SNE)
- Hierarchical clustering
- Logistic regression